Last week I published a piece about why I use six different AI models and why treating them as interchangeable is a mistake. If you haven’t read it, the short version is: different models are genuinely better at different jobs, and the engineers who’ve figured that out are quietly running rings around everyone else.
What I didn’t cover, what I deliberately parked for a separate article, was the money.
Because that’s where this gets interesting. And urgent.
The bill is coming
Most companies right now are in the honeymoon phase with AI spend. Subscriptions get approved, API keys get shared around, and nobody’s asking hard questions about what the organisation actually got for the investment.
That changes at year-end review. It already is changing. And when someone in finance opens the token usage report and asks “what did we get for this?”, the companies with a good answer will be the ones that treated token spend the way any sensible engineering team treats any other resource: with actual strategy.
The ones without a good answer will be the ones who did what most people do by default.
They used their most expensive model for everything.
Not all tokens are created equal
Here’s the thing most people don’t think about when they reach for Claude Opus or GPT-5 for every task: there’s a 5x pricing gap between the top and bottom tier of models from the same provider.
Current API pricing (April 2026, per million tokens input/output):
| Model | Cost | Best for |
|---|---|---|
| Claude Opus 4.6 | $5 / $25 | Complex design, deep reasoning, multi-file architecture |
| Claude Sonnet 4.6 | $3 / $15 | 95% of coding and building |
| Claude Haiku 4.5 | $1 / $5 | Testing, sub-agents, validation, repetitive tasks |
| Grok 4.1 Fast | $0.20 / $0.50 | Brainstorming, adversarial critique (free tier available) |
| Gemini Flash | ~$0.10 / $0.40 | Large-context triage, quick summarisation |
That’s Opus costing 25x more per output token than Gemini Flash. For a task where both produce the same result, using Opus isn’t being thorough. It’s being negligent.
And across a team running hundreds of tasks a week, that gap compounds fast. We’re talking tens of thousands of pounds a year in pure waste, on work that didn’t need the expensive model and isn’t any better for having used it.
The mental model that actually works
Stop asking “which model is best?” and start asking “which model does this job need?”
Think about it the way you’d think about staffing a software team.
Your principal engineer is brilliant, expensive, and finite. You don’t ask them to write unit tests, review boilerplate, or summarise a Jira ticket. You use them where their judgment is genuinely irreplaceable: the architecture calls, the decisions that stay expensive if you get them wrong. Make sure everything else flows to the right level.
AI model selection is exactly the same problem.
Opus is your principal engineer. Sonnet is your senior developer. Haiku is your capable junior who’s surprisingly good when the task is well-defined. Grok is the brutally honest colleague who’ll tear your idea apart for free, which is exactly what you want before you’ve committed any real resources.
The best AI users I know don’t just prompt better. They assign work better.
The opportunity cost nobody talks about
Here’s the part that really matters, and I never see it discussed.
On consumer plans (Claude Pro, the subscription tiers), you don’t have unlimited tokens. You have a session allocation. Once it’s gone, you wait.
But here’s what makes this worse than most people realise: every message you send doesn’t just cost you the tokens in your new question. It costs you the tokens to re-read your entire conversation history. LLMs are stateless; they have no memory between calls, so every new message includes every previous message as input. By message 30, you might be sending 20,000 tokens of history just to get a 100-token answer. A long Opus chat doesn’t just charge you for your question. It charges you Opus rates to re-read everything you’ve ever said to it.
So if you burn Opus tokens on brainstorming you could have had for free on Grok, those tokens aren’t available when you actually need Opus to do the thing only Opus can do.
There’s a compounding trap on top of this. When Opus gives you a partial answer and you reply with a correction, that failed attempt is now baked into the conversation history, re-read on every future turn. Use the edit button on your original prompt instead. It replaces the branch, removes the mistake from history, and stops paying the re-reading tax on a dead end.
I’ve caught myself doing this. Starting a planning session with Claude (which is my natural reflex) and realising halfway through: I’m not building anything yet. I’m just thinking out loud. This should be Grok.
The discipline of routing tasks to the right model before you start is what separates people who consistently ship good work from people who hit their usage limits at 3pm wondering where all their tokens went.
Route the work, not the ego
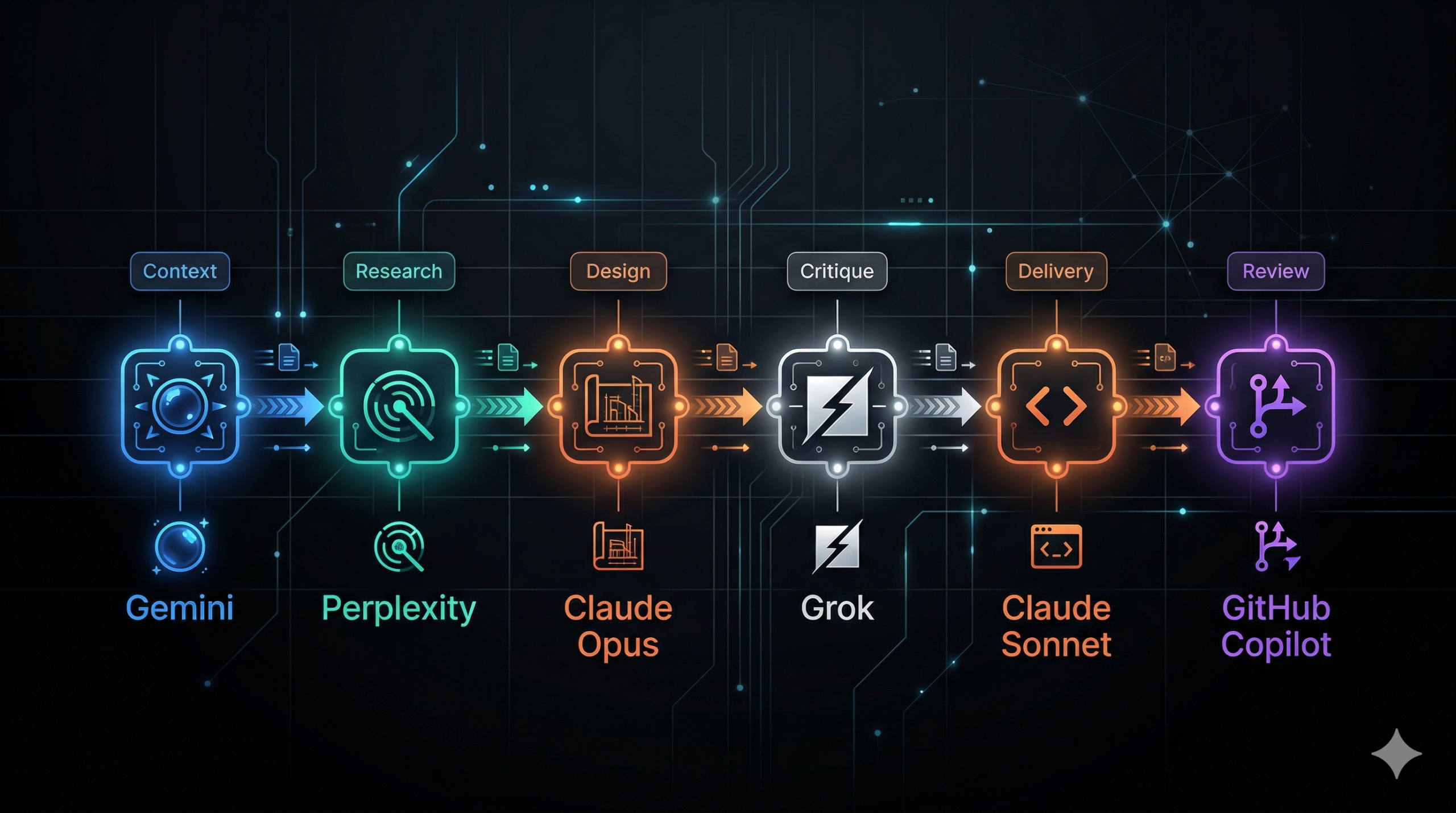
Here’s my actual routing flow. I covered the what in the multi-model piece. This is the why, through the lens of cost.
Brainstorming and adversarial critique → Grok (free tier)
Before I spend a single precious Anthropic token on an idea, I’ll throw it at Grok. Grok is ruthless. It’ll find the holes, tell me what’s wrong, push back without the diplomatic softening you sometimes get from Claude. That’s exactly what I want before committing any real resources. And it costs nothing. Why would I use anything else at this stage?
Research → Perplexity
Every time. It’s hypertuned for research in a way that genuinely surprises me. Citations, synthesis, current information: Perplexity just gets this right. So that’s where the exploratory work goes, not my Claude quota.
Large-context triage → Gemini Flash
When a task involves scanning a large codebase or a massive document set, Gemini Flash at near-zero cost handles the breadth. It identifies what matters, isolates the relevant sections, hands a focused context to the model that actually needs to think about it. You don’t need a principal engineer to read the entire file tree; you need them to look at what the triage found.
Architecture and complex design → Claude Opus
This is where the premium tokens earn their keep. When the reasoning chain matters, when a wrong decision stays expensive for years, when I need a thinking partner who’ll push back correctly rather than just agree: that’s Opus. Not because it’s the most powerful model available, but because this is the class of task where the quality difference is real and the stakes justify the cost.
95% of actual coding → Claude Sonnet
This surprises people. The SWE-Bench gap between Sonnet and Opus is now less than 1.5 points. For standard implementation work (which is most of it), Sonnet is faster, cheaper, and produces the same result. The only time I genuinely need Opus for coding is when a change spans massive context with complex interdependencies. That’s maybe 5% of my build work. Everything else is Sonnet.
Testing and sub-agents → Haiku
The one most people overlook. Test execution doesn’t need frontier intelligence. It needs speed and reliability. Haiku at $1/$5 per million tokens can run a lot of tests. Burning Opus tokens on a test run is like asking your principal engineer to check the CI pipeline. Technically they can; it’s just an appalling use of their time.
If you’re running multi-agent pipelines, the economics here are even more pronounced; every sub-agent call compounds. I wrote about what agentic systems actually look like in practice if you want the concrete version of this.
What this looks like at scale
For a medium coding task – say, 200k input tokens, 50k output – the numbers look like this:
- Pure Opus workflow: ~£1.20 – £1.50 per task
- Mixed routing (Haiku for tests, Sonnet for implementation, Opus for design): ~£0.20 – £0.35
Scale that to a team running 100 tasks a week. The annual difference runs to tens of thousands of pounds, with better results, because each model did what it’s actually good at rather than one expensive model doing everything adequately. For a real picture of what that kind of build actually involves, my journey building an agentic developer gives you the unfiltered version.
The enterprises that will look back on their 2026 AI spend with a clear conscience will have done three things: defined a model routing policy, used batch processing and prompt caching where possible (both Anthropic and OpenAI offer 50% discounts for batch API; prompt caching can cut input costs by up to 90% for repeated context), and treated token spend as an engineering metric, not just a finance line.
Cost per task. Quality per token. Routing efficiency. These are performance indicators. The teams that measure them will outperform the ones that don’t.
Three questions before you open any chat window
I’ve simplified my own decision process to three questions. You can use these starting tomorrow:
- Does this require deep reasoning, or is it just execution? Deep reasoning (architecture, ambiguous problems, multi-system tradeoffs) earns the premium model. Execution that follows a clear spec doesn’t.
- Could a cheaper model get me 80–95% of the way there? Be honest. Most tasks have a 90% solution available at a tenth of the cost. If 90% is good enough for the task, 90% is the right answer.
- Am I using a premium model because I need it, or because it’s convenient? Convenience is the real budget killer. Defaulting to the model you have open is how waste compounds invisibly.
The principle
The people who win with AI in the next two years won’t be the ones using the most powerful models.
They’ll be the ones who worked out that intelligence is a finite resource — and spent it accordingly.
Token ROI is the discipline of using the smallest model that reliably does the job, and reserving your expensive reasoning for the moments where quality actually changes the outcome.
What’s coming next
I’ve been thinking about building something to make this easier: a model selector tool where you describe what you’re trying to do and get a current, task-calibrated recommendation on which model to use. Not a static list (those go stale fast as models shift), but something live. I’m calling it the LLM Council; the best recommendation isn’t one model’s opinion, it’s a consensus view that updates as capabilities evolve.
If that sounds useful, say so in the comments. I’ll build it if there’s appetite.
Miss the companion piece? Not All AI Is Equal — Stop Pretending It Is covers the which model for which task. This one covers why it matters economically.