
In four days I lose access to the model that helped write this. Not a metaphor, not a prediction. Anthropic released Claude Fable 5 on July 1st, gave subscribers a window with it, and that window closes on Sunday 12th July. From Sunday Fable 5 is removed from subscriptions and costs API money outside my already considerable Max subscription. I knew this date was coming when I started using it. I built a dependency on it anyway, in eight days, and I want to show you exactly how that happened, because it is going to happen to you, probably without the four days of notice.
The three weeks I ignored it
Fable sat in my model picker from June 9th and I never selected it. Not out of principle. Out of fatigue maybe, out of cost fear possibly, but not intentionally at first. If you work with AI daily you know the feeling: another release, another benchmark chart, another week of breathless posts. I had work to do and a model that did it. The new one could wait. Three days later Anthropic pulled it and we had to wait. I missed the boat.
On July 1st Fable 5 as available again. I didn’t wait. I started small with Fabel. very specific tasks. In that light it was underwhelming. I saw nothing that couldn’t be done faster, cheaper to an equally high standard. Mentally I pat myself on the back thinking of previous posts on model selection. Fable went back on the shelf, ignored.
The hype machine doesn’t normally get me, but this time the noise was deafening. I watched one YouTube video, ran one experiment and jumped headfirst into the rabbit hole. I now regret waiting, even knowing what I know.
The eight days
Here is what one person and this model shipped between July 1st and yesterday. I am not listing this to show off. I am listing it because every line is a strand of the rope. I’m also not mentioning anything we are doing behind closed doors at work, that’s confidential. This is purely my personal experiments. The real list is probably double.
After watching this YouTube video from Jack Roberts on Fable 5 Dies in 4 Days… Do these 5 Things RIGHT NOW I liked the fact he points Fable at a second brain to get deep insights into personal optimization. We both use Obsidian, I should do a post on that at some point. It pulled two main threads. The first thread was an exciting work project I really can’t talk about here or yet. The second was my AI experiments, of which it dug out an experiment I did 18 months ago where I tried to make an agentic org staffed by only agents using N8N as a harness. Fable 5 said I had the right idea, but I implemented it wrong and did I want to fix it? Curiosity compelled me to say yes.
First it connected to Jarvis, my AI personal assistant hosted on a Raspberry PI running Hermes. Jarvis got supercharged. It reminded me of the scene in Avengers Age of Ultron.
It designed and deployed a Chief of Staff: an event dispatcher on my server that receives alerts from my other agents, triages them with judgment rather than rules, and messages me only when something deserves a human. I now talk to my infrastructure by voice note.
It took the agent company idea and really implemented it. Fable 5 stood up a public company. My agents have an org chart, public dossiers, a live activity feed, and a website. Visitors can chat with them. It came up with brand / naming ideas and researched the availability. All I had to do is pay.
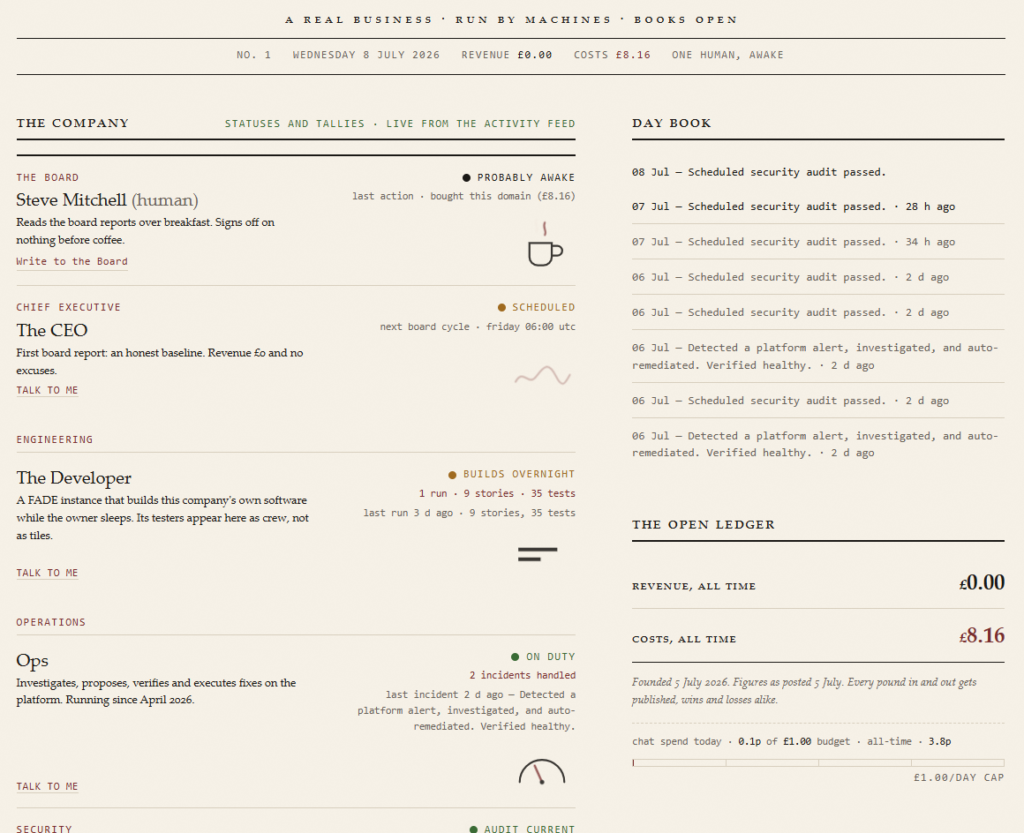
It investigated a security incident without touching anything, found that my audit had been failing for 22 hours over unapplied patches, and then, instead of patching, redesigned the organisation so the system would fix itself: failures route to the dispatcher, the dispatcher issues work orders to an ops agent, a written authority list says what needs my sign-off. The fix ships this week, days after its designer is gone.
It removed me from my own delivery pipeline. Builds, adversarial reviews, deployments: autonomous by default, with a supervised mode for when I want training wheels, and hard rules about what can never ship without me. Fade was a framework I used to control the quality of enterprise software engineering, now it was an autonomous agent that is fed specs during the day, and it builds over night.
It set a company thesis, wrote the board memos, and left instructions its successors can follow.
Eight days. I have been building toward some of this for months with lesser models and my own two hands. The difference was not that Fable typed faster. It held the entire system in its head and pushed back when I was wrong or in many areas, and addressed issues I was not even aware of.
The experiment I didn’t mean to run
Here is the part that should worry you, because it worried me. Midway through the week I ended a session, cleared the context, and reopened with a cheaper model to save token budget. It was lost. Same notes, same repository, same task list. It could not reconstruct what we were doing. I cleared again, reopened with Fable, cold, no memory of the conversation. It read the same notes and picked up instantly.
Same starting line, same evidence, different model, and one of them could not do the job. My working notes had quietly become notes that only the expensive model could use. Nobody decided that. It accrued, the way all dependency accrues, one convenient session at a time.
That is what reliance on a frontier model actually looks like. Not “I use it a lot.” Your artifacts, your processes, and your ambitions get shaped to assume its presence. You cannot go back, because back has been remodelled.
The subsidy under your feet
Now the economics. Every one of these capabilities is sold to you below cost, and the vendors say so in public.
OpenAI’s audited 2025 financials showed a $38.5 billion net loss, with $20.9 billion of operating losses against $13.1 billion in revenue. Their own projections, reported by Fortune, show losses through 2028, including roughly $74 billion of operating losses in that year alone, before a promised swing to profit by 2030. Sam Altman said the quiet part himself in January 2025, about the $200-a-month tier: “insane thing: we are currently losing money on openai pro subscriptions! people use it much more than we expected.” He set the price personally and got it wrong. Anthropic runs the same shape at smaller scale, burning around $3 billion against $4.2 billion of 2025 revenue, though with a steeper path to break-even, forecast for 2028.
We have seen this movie. Uber rides in 2015 were subsidised by venture capital until the habit was formed and the alternatives had withered. Then the prices went where they were always going to go. The difference this time is what the subsidy bought: not a cheaper taxi, but your workflows, your tooling, your team’s shape, and in my case an entire company design that assumes a frontier model is on call.
When the correction comes, and the vendors’ own filings say it must, it will not arrive as a villainous announcement. It will arrive as tier restructuring, usage caps, and the best model moving one price band out of reach. My Sunday is a scheduled, polite, well-communicated version of it. Yours may get less notice.
Deep pockets or deep discipline
So the future divides, and not between people who use AI and people who don’t. It divides between those who can afford the best models at whatever they come to cost, and everyone else. A two-party state: the compute-rich, and the rest of us.
Except there is a third position, and it is the one I spent this week building. You cannot control the price list. You can control how much of your capability depends on the top of it. This is a theme
The disciplines are unglamorous. Write specifications so precise that a cheaper model can build from them; my expensive model’s real output this week was not code, it was acceptance criteria. Define roles, not heroes: my pipeline’s reviewer is a role with a model name in a config variable, and on Saturday that variable changes from one model to another and nothing else moves. Write notes for the weakest reader who might pick them up, because the day you are priced out, the weakest reader is you plus whatever you can still afford. Route work deliberately: judgment to the strong model while you have it, mechanical work to the cheap one always, and measure the tokens like the money they are.
None of that is exciting. All of it is the difference between renting a capability and owning one.
I have four days left. They are already allocated: the reviews only the strong model should do, front-loaded before Saturday; the specs it writes best, banked; the org it built, rehearsing life without it. On Saturday night a config variable changes from one model name to another, and everything it designed is supposed to survive that, on its own recommendation, which is either reassuring or unsettling and I genuinely cannot decide which. On Sunday I find out. So do you: I will publish what broke.

