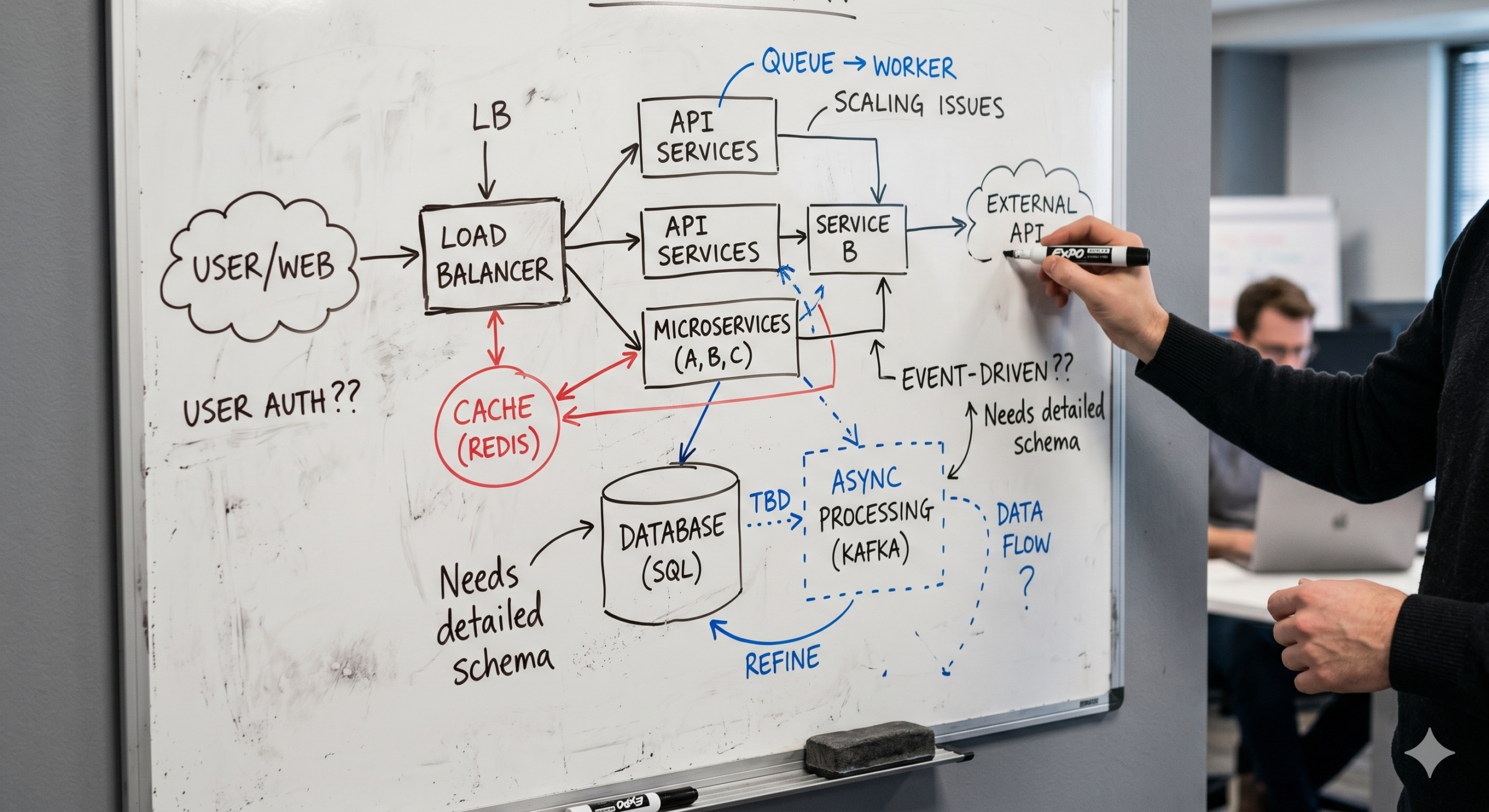
A couple of weeks ago I was in our Chicago office, working with a group of colleagues as we looked to leverage our agentic framework on one of our premier products. The goal of the week was a thought experiment: using our agentic framework, could we leverage AI to completely modernise the tech stack. Ordinarily this would be 12 months of work. We had 5 days.
During the very first session, my colleague Jim Pucci was going through a PRD, a project requirements document I use to drive agentic development through FADE, our framework for keeping agentic development on the rails across long sessions. The PRD was solid. Requirements were clear. The agent was about to start building.
Jim read it, looked up, and asked:
“These are the requirements. How do you know what you’re going to build?”
I didn’t have a clean answer. And the more I sat with that question, the more I realised it had exposed a gap in my own framework.
What FADE actually does
FADE injects context. It locks in the frame the agent works inside: vision, constraints, coding standards, architectural principles, the things you’ve learned from previous sessions. It’s why I can hand an agentic developer a complex task at 5pm on a Monday afternoon and have it work all night so we can pick up again on Tuesday morning to working software to review, built to standard.
FADE.md sets the frame. progress.md tracks state. learned.md captures memory across sessions. It works. I’ve shipped real things with it.
But Jim’s question was about something FADE doesn’t do. The frame tells the agent the world it’s building in. The PRD tells it what the business wants and why. Neither tells you, before a line of code is written, what is actually going to be built.
That decision: the architecture, the structure, the patterns, the schemas, the contracts between modules. It’s happening at runtime, inside the reasoning engine, on the fly. Two FADE runs against the same PRD, with the same frame, can produce materially different builds. You only find out which one you got after the fact.
The role we forgot
In a normal engineering team, this isn’t how it works. The PRD is a contract between the business and the architect. It says what the business wants. The architect’s job is to translate that into a spec: how it will be built, what the structural commitments are, which patterns will be used. That spec is then the contract between the architect and the developer. The developer implements the spec faithfully, not re-derives the architecture from requirements every time.
We’ve had this model for decades. Classical software engineering with the roles named honestly.
What’s new is that the agent has been quietly doing the architect’s job inside the reasoning engine, without anyone signing off on it. FADE gave it enough frame to do that job reasonably well. That’s why it works at all. But it never made the architect’s output a visible artifact. The build decisions are real. They have consequences. Right now they’re invisible until they’re already code.
Jim’s question lands because in human teams, the architect’s work is written down and reviewed before the build starts. With agents, we skipped that step and called it productivity.
What plan mode gets right, and where it stops
GitHub Copilot and Cursor have plan modes now. Before the agent touches your code, it tells you what it’s going to do. You can push back. That’s a step forward.
But it’s still one developer, in one session, reviewing what one agent is about to do. The plan isn’t a document. The architect doesn’t see it before the work starts. Security doesn’t sign off on the auth model. QA finds out what was built when there’s something to test. One person saw the decisions. Then they became code.
For a solo project, fine. For a team in financial services, insurance, or healthcare, that’s a problem.
These industries have governance processes and audit requirements for real reasons. When something goes wrong, the question isn’t “what did you build.” It’s who reviewed the approach, when, and what they approved. A plan mode session doesn’t produce that evidence. A private FADE.md doesn’t either.
The gap isn’t developer visibility. Developers have that. The gap is that there’s no written spec, reviewed and agreed before the build starts, that the whole team can sign off on. Not just the developer. The architect, security, QA — the people whose names go on the approval. In a regulated environment, where clients need demonstrable evidence that what you built is secure, testable, supportable, and built to scale, “the agent had a plan mode” isn’t an answer anyone will accept.
What the spec layer should look like
If FADE’s evolution is a spec layer between PRD and build, a few things follow.
The spec is owned by the architect role. That might be a human, or agent-assisted, or the agent drafting while a human signs off. The form doesn’t matter much. Somebody has to be the architect. Accountability sits there. The agent can propose; the architect signs.
The spec generator isn’t a blank-page exercise. It’s grounded in three inputs:
- The PRD, for intent.
- The standards, for constraints. The FADE frame already covers most of this.
- The existing codebase, for context. What patterns are already in use. What the auth model is. Where the seams are. What the team has already committed to.
A spec produced against the codebase fits the codebase. It can’t propose an architecture that contradicts what already exists without that contradiction being visible. The architect reviewing it sees “this reuses the existing pattern” or “this proposes a new one” as an explicit decision, not a runtime accident.
That makes the spec a negotiation surface. The agent proposes, the architect pushes back. “You’ve reused the auth module, good, but you’ve bypassed the rate limiter, fix it.” That conversation is worth having before the code exists, not after.
The bar I’d want to hold it to
Here’s a test for whether the spec layer is doing its job: a different agent, or the same agent in a fresh session, should be able to pick up the spec and produce substantially the same build.
If they can, the spec is committing the architectural decisions properly. If they can’t, the spec is too thin and too much is still being decided at runtime.
That’s a falsifiable bar. You can actually tell whether you’re winning.
What I haven’t worked out
I’m not going to pretend I’ve solved this. There’s a stack of open questions:
- Granularity. Is the spec one document per PRD, or per feature, or per module? Probably depends on size, but I haven’t drawn the line yet.
- Sync. A spec drifts from the PRD on one side and from the code on the other. How do you keep all three honest as the build evolves?
- Codebase reading. This is the hard bit. A spec generator is only as good as its ability to actually understand the codebase it’s reading. Most agents read code shallowly: grep for keywords, miss the actual structure. A spec generator that reads badly will produce specs that look grounded but aren’t, which is worse than no spec at all because it hides the architecture decisions behind a veneer of rigour.
That last one is the real engineering challenge. It’s the next post.
The principle
Agents can be developers. Agents can assist architects. But somebody has to be the architect. Their output has to be visible.
A PRD tells you what the business wants. It doesn’t tell you what you’re going to build. Until that decision is written down and signed off, you haven’t authorised anything. You’ve just hoped the reasoning engine picks well.
FADE gave me the frame. Jim gave me the question. The spec layer is what comes next.